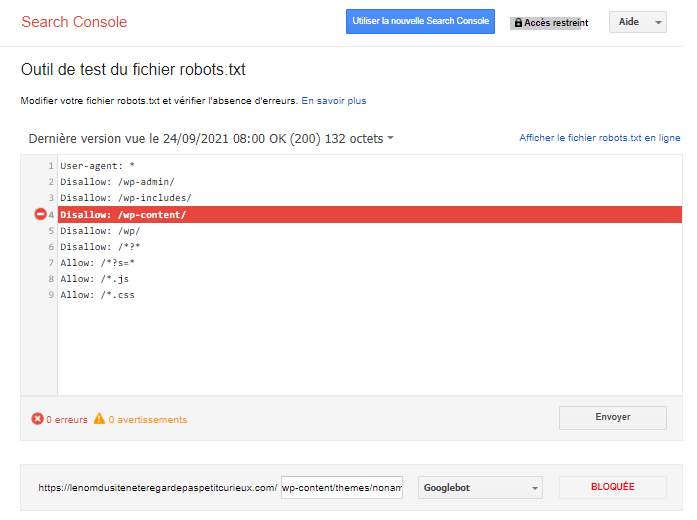
J’ai testé l’Outil de test du fichier robots.txt
 Le fichier robots.txt est un petit fichier texte placé à la racine du site qui permet principalement de bloquer l’accès à certaines URLs. Bien que facilement accessible et manipulable, même par les non développeurs sur les serveurs mutualisés, une mauvaise configuration peut causer de gros dégâts SEO pour le site.
Le fichier robots.txt est un petit fichier texte placé à la racine du site qui permet principalement de bloquer l’accès à certaines URLs. Bien que facilement accessible et manipulable, même par les non développeurs sur les serveurs mutualisés, une mauvaise configuration peut causer de gros dégâts SEO pour le site.
Justement Google a mis à la disposition des Webmasters un outil de test du fichier robots.txt. Voici les retours des experts de l’agence SEO Tactee suite aux tests effectués.
Allow VS Disallow
On utilise en général uniquement la fonction Disallow qui sert à interdire le crawl d’une page ou de formats d’URL un peu plus élaboré en utilisant des REGEX simplifiées (Expressions régulières).
Voici deux REGEX utiles dans le robots.txt :
- La wildcard sous forme d’astérisque * est une Joker qui permet de remplacer une séquence par n’importe quel signe.
- Le dollars $ sert à spécifier la fin stricte d’un format d’URL
Le Allow est l’inverse du Disallow : il indique au bot du moteur de recherche qu’il est possible de crawler le format d’URL spécifié. Il est beaucoup moins utilisé que le Disallow, ce qui parait normal car par défaut, tout ce qui n’est pas en Disallow est autorisé au crawl donc en Allow.
J’ai donc testé de mettre des commandes contradictoires dans l’outil de test du fichier robots.txt afin de voir qui l’emporte entre Disallow et Allow :
Pour tous les Tests ci-dessous j’ai utilisé l’URL suivante : site.tld/test/ab/xyz avec le bot Googlebot :
![]()
> Est-ce que l’ordre entre le Allow et le Disallow a une influence ?
La ligne de commande surlignée (rouge ou verte) est elle qui prend le dessus sur les autres lignes de commande du fichier.
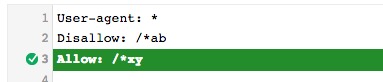
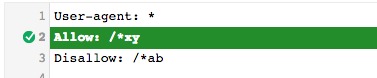


On constate que l’ordre entre Allow et Disallow ne change rien et qu’à nombre de signes égal, le Allow prend toujours le dessus.
> On va donc vérifier si avec des nombres de signes différents, il y des changements dans la commande qui prendra le dessus :

On remarque que la commande avec le plus de signes prend le dessus
> Mais est-ce que la wildcard * est comptée comme un signe et peut influencer dans la lutte entre Allow et Disallow ?
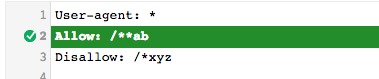

Donc le nombre de wildcard * serait également comptabilisé comme un caractère. Est-ce un bug de l’outil ou est-ce appliquer en vrai ? Ça n’a pas beaucoup de sens en tout cas…
> Et le $, est-ce comptabilisé comme la wildcard * ?


On voit que le dollar compte aussi comme un caractère. Donc tous les signes utilisés pour une expression régulière seraient comptabilisés pour voir quelle commande prend le dessus sur l’autre.
Pour résumer :
- la commande qui a le plus de signes (REGEX comprises) dans le chemin d’URL l’emporte sur l’autre
- s’il y a le même nombre de signes dans la commande, le Allow l’emporte sur le Disallow
Test sur le User-Agent
Le User-Agent sert à préciser à quel robot crawler les commandes justes en dessous s’appliquent.
Petit test pour voir quelles commandes prennent le dessus en cas de contradiction dans les règles avec User agent global * et plus spécifique comme Googlebot
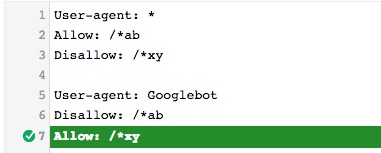
Le User Agent le plus spécifique (ici Googlebot) prime (logique).
Est-ce qu’on peut mettre un noindex dans le fichier robots.txt ?
Je n’ai pas trouvé de traces dans la documentation Google sur l’utilisation du noindex (si vous en avez je veux bien que vous me la partagiez en commentaire), mais j’ai voulu tester le noindex dans le fichier robots.txt

On voit que le noindex est un code valide mais pas le index tout seul. Donc le noindex dans le fichier robots.txt serait toujours pris en compte (sauf si l’outil bug).
Après il faut faire attention, car si ce noindex dans le fichier robots.txt fonctionne il est probablement beaucoup moins fiable que la balise <meta name="robots" content="noindex"> dans le <head> des pages concernées ou du X-Robots-Tag: noindex en entête http, pour la simple raison que lorsque Google bot découvre une page depuis un backlink externe, il ne visite pas forcément avant le robots.txt avant de crawler cette page (enfin à ma connaissance). Si vous avez déjà testé, n’hésitez pas à partager en commentaires.
Personnellement je n’utilise et n’utiliserai probablement jamais le noindex dans le robots.txt… quoique pour des optimisations sur certaines plateformes de CMS en Saas où on ne peut pas modifier les <head> mais seulement le robots.txt, ça peut être une solution de recours.
Wildcard * vs $ vs Rien
Je me demande aussi si cela revient au même de mettre une wildcard, un dollar ou rien en fin de commande dans un Disallow :




On remarque que :
- La wildcard et ne rien mettre à la fin reviennent au même : les URLs concernées sont celles qui continuent ou se termine par les caractères en bout de ligne – ex : les commandes
Disallow: /abetDisallow: /ab*concernent aussi bien l’URL site.tld/ab que site.tld/abc. - Le dollar sert bien à indiquer la fin de l’URL comme prévu.
Dernière version du robots.txt
Il y a aussi une fonctionnalité permettant de voir les dernières versions du robots.txt, ce qui peut être utile pour vérifier s’il y a un rapport avec une baisse passée du trafic sur l’Analytics ou si des pages ont mis du temps à s’indexer par exemple…
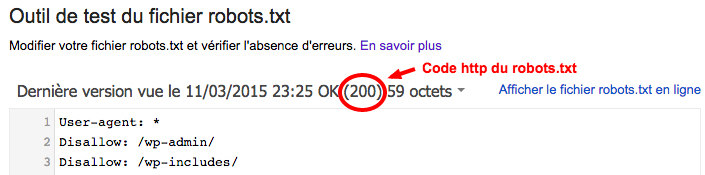
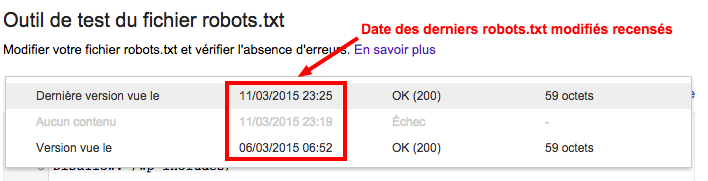
On y trouve aussi l’indication du code HTTP renvoyé par le robots.txt. Juste un petit rappel sur le code renvoyé par le robots.txt :
- 200 : tout est OK.
- 301 : Googlebot suivra cette redirection mais ça n’est conseillé que pour la redirection vers l’URL principale avec ou sans WWW ou pour un changement de domaine. Le robots.txt doit être à la racine du site.
- 404 : Cela revient au même que d’avoir un fichier robots.txt vide : aucune restriction de crawl pour les moteurs de recherche.
- 500 : Il faut corriger rapidement car lorsque Googlebot crawlera le robots.txt en erreur 500, il va considérer que le site à un problème et ne vas plus (ou moins) crawler le reste du site, ce qui se ressentira sur le trafic à court terme.
Autres erreurs à éviter avec le robots.txt
Si le fichier robots.txt à l’air simple d’utilisation, il faut faire attention à ne pas commettre d’erreurs néfaste au référencement. Les 2 erreurs les plus courantes sont :
- Laisser un
Disallow: /qui empêcherai les moteur de recherche de crawler tous le site. - Laisser en Disallow un format d’URL qu’on souhaiterai désindexer avec une meta noindex (Google ne pouvant pas crawler ces pages, il ne pourra pas les désindexer)…
Debrief
L’outil de test du fichier robots.txt est très utile pour vérifier que certaines URLs ne sont pas bloquées par le fichier robots.txt qui peut parfois contenir des dizaines de lignes avec différentes Expressions régulières ce qui la rend illisible à l’oeil nu.
Après ces tests, j’ai appris que le Allow pouvait donc servir à quelque chose : si on empêche le crawl d’un répertoire avec un Disallow, on peut autoriser le crawl d’une URL plus spécifique de ce même répertoire avec un Allow.
En ce qui concerne le duel Disallow VS Allow, on apprend qu’avec un tronc commun, la commande avec le plus de caractères l’emporte et qu’en cas d’égalité le Allow prend l’avantage. On apprend aussi qu’on peut ruser avec l’ajout d’autres Expressions régulières qui son comptées comme des caractères.
N’ayant pas fait de test en réel sur des sites pour ce duel Allow vs Disallow, je ne peux affirmer si certains résultats sont des bugs de l’outil (un outil Google buggé? non impossible!), ou si tout fonctionne correctement.
Si vous avez des retours d’expérience la dessus, je vous invite à les partager en commentaires.
Liens utiles
- https://support.google.com/webmasters/answer/6062596
- http://www.webrankinfo.com/dossiers/indexation/crawl-respect-robots-txt
- http://www.yapasdequoi.com/seo/3519-robots-txt-url-encodees-test.html (Très bon test sur les caractères spéciaux dans le robots.txt)